Hello, and welcome! Having relied on others to get thoughts online in blog format, I thought I’d take a stab at it. This blog is TGDIO approved, that’s a nice flexible wrinkle to have – being a publisher. This first blog wasn’t intended to be on the topic in the headline as I’ve been working on another topic for quite some time now and then more technical detail keeps side-tracking that blog. Maybe that one shows up at some point. Meanwhile, a topic near and dear to many of us is first up. What was the seed for this one? Please take less than 2 minutes to listen to this snippet as to why Infinidat felt the need for an All-Flash Array (AFA) and then come back.
Now if that link aged-off, the crux of what CEO Phil is saying there is even though Classic Infinibox is faster than generic AFA (true in most cases), the need for iBox Solid State Array (SSA – Infinidat is referring to their AFA as SSA) is to address the growing need for a class of workload that benefits from AFA. Just what is that class? Well, good question. Let’s see if we can see where that iBox SSA might be a “better fit.” First, a look at where there is a gap – if you will. Buckle up buttercup, we’re going on a Latency Grand Tour!
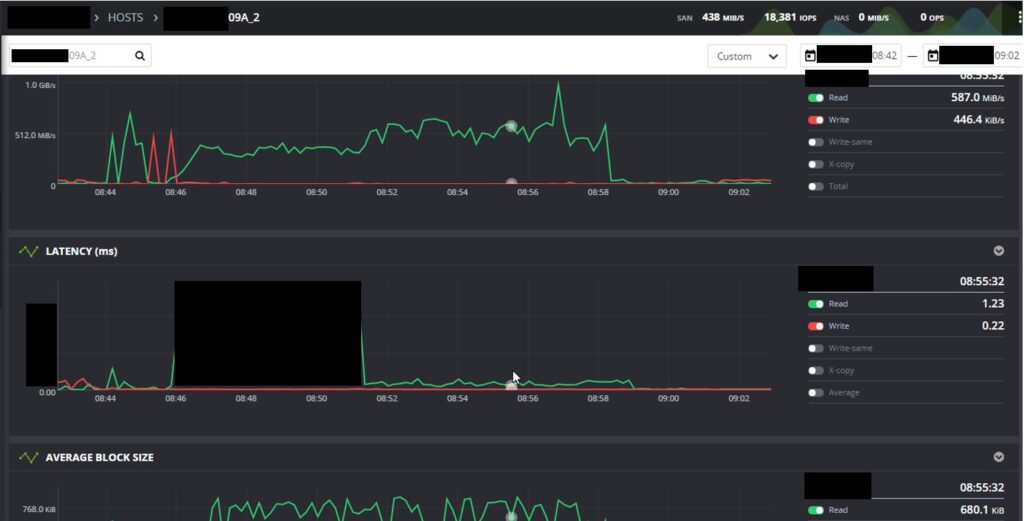
Don’t get nervous here. The intention isn’t to bash or embarass. It is to inform, or at least that’s what I’m trying to do here. You see that iBox Classic image above? I’ve purposely grayed out a number of areas. You see that big box on latency? For a period of time there latency spikes up quite a bit. Not shown is cache miss rates or decrease in cache hit rates. From the bandwidth above it, we can infer that the host could process more as the bandwidth increases as the feed rate speeds up – tracking the decrease in latency. The preeminent caching algorithms have kicked-in, we are able to get ahead of demand curve. The IO is being served by cache, not read from NL-SAS. I’m hovered over an arbitrary point, at that point we see 680KB IO being delivered in 1.2 ms. That’s excellent.

AmIRight or AmIRight?
I’ll spend more time contrasting the latency profile above – in a bit. But for now, consider that the process that ran there might run faster on an all flash array as that AFA would get a head start. And the run is pretty short in duration – that’s an important point. However, I’ve seen a number of AFAs in the last few years, when pulling large IOs off storage (that has been deduped) additional response time is the result. But let’s move on from that. Look at this screenshot below. Might be a bit of an eye test. Look at the one below that, we are more interested in that zoomed in portion.

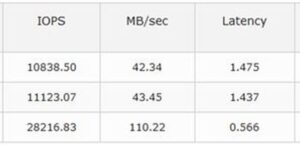
The story above is a monthly run that needs to fit into a 24 hour run window and migrating from one storage subsystem to another AFA, things actually went slower, many hours slower. As it turned out, the top two volumes were created a certain way, the bottom volume was created with no data reduction in play. As you can see, the bottom volume latency is nearly 1/3 the latency of the other two volumes. Going back a few years, we were quite content with 1.4 ms small random IO. Now? Not so much. Part of the pressure to perform now comes from AFA storage subsystems that are undergoing refresh cycles and NO ONE wants things to run slower and introduce business impact that was fixed years before. Latency and focus on latency is even more important these days. So let’s pretend a Classic Infinibox was the replacement storage subsystem for the above. Are we fairly confident a classic box would go even faster on the weekend run versus the AFA box above? Why yes. Much of the IO would be cache hits (once the caching algorithms kick in.) Here is a lift quote that bolsters our confidence:
[The] InfiniBox and InfiniBox SSA both deliver 95% of the data reads from DRAM, the latency is generally 20 microseconds (μs) to 40 μs depending on the workload, according to Bullinger. But if the SSA model has to retrieve data from the back-end storage, the latency would be 200 μs to 300 μs, compared to more than 1 millisecond with the disk-based InfiniBox, he said. Reference
Yes, more than 1 millisecond to NL-SAS – indeed. If we revisit our 680 KB IO above and we ask ourselves can’t that go faster than 1.2 ms for retrieval, why so slow? Well, that’s where “depending on the workload” comes in on the above quote. Larger IOs take longer. More buffers to copy, more staging of buffers, more interrupts, etc. Those 680 KB IO cache hits, take a time to get to the host. Take a gander at the following chart.
A 256 KB IO takes over 150 microseconds to transfer over 16 gbit FC fabric. The wire transfer time of a 680 KB IO is right at 0.5 ms. A cache hit and landing in a host for an IO this large showing 1.2 ms response is expected. Note above that in the same column, the transfer time of a 32 KB IO is a negligible (at least for now) 5 microseconds.
We now arrive at the place where we can suggest where the Infinibox SSA is a better fit and we’ll focus on one of those. Not limited to just these classes, but I’d posit these:
- Trading
- Military
- Benchmarks
One of my long standing pet peeves is a certain “benchmark” that a large healthcare software leader insists on running prior to certification. This “benchmark” is basically a random IO test. For positioning of your storage solution, do good and you are blessed at their highest tier, others are relegated to a lesser tier which often relegates the lesser tier to also-ran status. Never mind in actual day-to-day the Infinibox would outperform. Now granted, a patient calls up to make an appointment, long stale records pulled up and the AFA pulls the record faster. Playing both sides of the debate, the upside of such “benchmarking” no doubt allows the vendor to greatly limit performance related calls. Additionally, it eliminates the need to certify boutique solutions. Run the test and pass back the results – get a thumbs up or down. In a similar need for speed vein, you can also imagine excellent speed of every single IO in real time military applications and trading is a must have. You don’t want an IO taking over 10 milliseconds to fetch data with an incoming missile as part of end-user need.
The tour is reaching its apex, let’s turn to barn burner latency in a preview? model F1303NV or maybe just a lab experiment – and nothing more? Look at these random 4K IOs in this screenshot below. Reference

That’s 40 microseconds for random writes and 20 microseconds for random reads. Compare that to the 560 microsecond random 4K results above. But that is an expensive SCM-based caching layer. Switching gears a bit, remember the 100 microsecond latency DSSD? DellEMC no doubt saw little uptake post billion dollar purchase, perhaps for Trading (Exchanges) solutions only and not enough of those to continue with DSSD. Even worse – bad timing as storage class memory (Optane) showed up and DSSD was axed about the time Optane shipped. Opportunity to go through the ashes there and perhaps comment on that at some point. Perhaps the DSSD lesson, the slowness of NVMe-oF uptake, financial factors, shelved or greatly delayed the F1303NV (NV = NVMe it seems.) However, the F1303NV has no peers. Will we see a box like that or just modest SCM as a tier industry-wide? Over 2.5 years later, it appears the F1303NV isn’t seeing the light of day. Want a guess? Glad you asked. I’ll guess that the iBox SSA made more sense. Cached data heated up to an SCM layer is a nice to have, but with DRAM cache hits in the 90%+ range AND a ceiling of 300 microseconds on random small IO, the SSA is “good enough.” It wins all the head to head competition. We are approaching latency singularity here folks, it is a thing of beauty.
TGDIO Closing Ruminations
So what’s the point or take away? Tail latency is a real thing. From that DB run in that first screenshot, we can see it takes a while to get going. Having reviewed numerous iBox performance views, we (collectively) seldom see cache misses beyond 3% (SSD + DRAM.) Even with the warm-up misses, I can assure you that run in the screenshot at the top was faster than the former solution. However, would that same run on a generic AFA beat the Infinibox? Possibly. It would have a nice head start. Compare and contrast the 24 hour weekend run. Initial slowness until algorithms kick-in wouldn’t be a concern. The initial tail latency would be more than made up for; the Classic Infinibox would no doubt run far faster over the weekend with 90%+ DRAM cache hits.
We see the Infinibox SSA has a 300 microsecond ceiling on small IO which would more than make up for any AFA RFP checkbox or nasty gateway benchmark (cough.. random IO test.. cough… cough) as a pre-req. Plus the end user would not experience an occasional “hitch” on data retrieval. It would be snappy at all times. And as Infinidat points out, the Infibox SSA is beating any and all in head-to-head match-ups for POC and otherwise. Very real tail latency, but perhaps inconsequential tails for the most part. What would you consider the SSA to be a best fit and why?
1 Comment
Phil Connors · February 9, 2022 at 9:31 pm
Rob – excellent job here, nice article and well put together. I plan on doing something similar for security hoping it might get me some work after I retire.